本書は次の英文資料を日本語訳したものです。
不備や質問がありましたら、訳者にご連絡いただければ幸いです。
2013/03/16
湊 隆行
turbo[at]minato.tv
Overview | 概要
Purpose | 目的
このチュートリアルでは、G1 ガーベジコレクタの基本的な使用方法と、Hotspot JVMにおけるG1ガーベジコレクタの使われ方を説明します。またG1 ガーベジコレクタの内部機能、コマンドラインオプション、および、ログに関するオプションについて説明します。
Time to Complete | 完読時間
およそ1時間。
Introduction | はじめに
このOBE (Oracle by
Example)では、Java仮想マシン(JVM)および G1 ガーベジコレクション (GC)を説明します。まず、JVMの概要について、ガーベジコレクションと性能を紹介しながら説明します。次に、CMSコレクタの動作手順を復習し、G1ガーベジコレクションの動作手順を説明します。最後に、G1ガーベジコレクタで使用可能なコマンドライン・オプションや、ログ出力のオプションを説明します。
Hardware and Software Requirements | ハードウェアとソフトウェアの要件
ハードウェアとソフトウェア要件の一覧:
o
Windows XP以降が動作するPC、Mac OS X、またはLinux。ハンズオンはWindows 7で行ったものです。すべてのプラットフォームでテストしたわけではありませんが、OS XまたはLinuxでも動作します。また、複数コアを搭載したマシンで動作するのを推奨します。
o
Java 7
Update 9以降
o
最新のJava 7 Demos and SamplesのZipファイル
このチュートリアルを始める前にやること:
o Demos and Samplesのzipファイルを同じところからダウンロードしてください。 ダウンロードしたzipファイルは、例えば「C:\javademos」ディレクトリ配下に解凍してください。
Java Overview | Javaの概要
JavaはSun
Microsystems社が1995年に初めてリリースしたプログラミング言語とコンピューティング・プラットフォームです。Javaはユーティリティ、ゲーム、ビジネスアプリケーションを含むJavaプログラムの原動力となった基礎テクノロジーです。Javaは世界中で850万(8.5億)を超えるパーソナルコンピュータと数十億のモバイル端末やテレビなどのデバイスで動作しています。Javaの全体像は、Javaプラットフォームを構築するための多くの重要なコンポーネントから構成されています。
Java Runtime Edition | Javaランタイム版
ダウンロードしたJavaには、Java
Runtime Environment (JRE)が含まれています。JREは、Java 仮想マシン (JVM)、Javaコアクラス、および、Javaライブラリのサポート機能で構成されています。この3つはすべて、コンピュータ上でJavaアプリケーションが動作するために必要なものです。Java
7で動作するJavaアプリケーションには、OSから起動するデスクトップアプリケーション、Java
Web Startを使用してWebから起動するデスクトップアプリケーション、あるいは、ブラウザ上で動作するWeb組み込みアプリケーション(Java FXを使用)があります。
Java Programming Language | Javaプログラミング言語
Javaは次の特徴を持つオブジェクト指向プログラミング言語です。
- プラットフォーム非依存 - Javaアプリケーションをコンパイルするとバイトコードを生成します。バイトコードはクラスファイル内にあり、JVMがロードします。アプリケーションはJVM上で動作するので、様々なOSやデバイス上で動作可能です。
- オブジェクト指向- Javaは、CやC++の多くの特徴を導入し、更なる改良を加えたオブジェクト指向言語です。
- 自動ガーベジコレクション – Javaはメモリ割り当てと解除を自動的に行うので、プログラムにはメモリ操作の負担がありません。
- 豊かな標準ライブラリ – Javaには、入出力処理、ネットワーク処理および、日付操作などを行うための非常に多くのオブジェクトをあらかじめ用意しています。
Java Development Kit | Java開発キット
Java仮想マシンは、Javaプログラミング言語を解釈するのではなく、特定のバイナリフォーマットであるクラスファイルを解釈します。クラスファイルには、Java仮想マシンの命令(もしくはバイトコード)、シンボルテーブルや、他の補助情報が含まれます。
セキュリティのために、Java仮想マシンは、統語的かつ構造的な制約を強く課したクラスファイルを扱います。有効なクラスファイルであれば、Java仮想マシンはJava以外のどんな言語でも処理できます。したがって、Java以外の言語の実装者も、Java仮想マシンの可搬性とマシン非依存のプラットフォームに惹きつけられて、その言語の動作環境としてのJava仮想マシンに関心を持ちます。 (1) The Java Virtual
Machine
Exploring the JVM Architecture | JVMアーキテクチャの探検
Hotspot Architecture | Hotspotアーキテクチャ
HotSpot JVMには、強力な機能(features)と能力(capabilities)の基盤をサポートするアーキテクチャと、高い性能とスケーラビリティを実現する能力(ability)をサポートするアーキテクチャがあります。たとえば、HotSpot
JVMのJITコンパイラは動的最適化を行います。Javaアプリケーション動作中に最適化を行い、システムアーキテクチャ向けの高性能なネイティブ命令を生成します。また、実行環境およびマルチスレッドで動作するガーベジコレクタは、継続的な改良により成熟した進化を遂げました。これらによりHotSpot
JVMは高性能なコンピュータシステム上でも高いスケーラビリティを提供します。

JVMの主要コンポーネントには、クラスローダ(Class Loader)、ランタイムデータ領域(Runtime
Data Area)と、実行エンジン(Execute
Engine)があります。
Key Hotspot Components | 主要なHotspotコンポーネント
下図では、JVMの主要なコンポーネントのうち、性能に関する部分をハイライトで示しています。
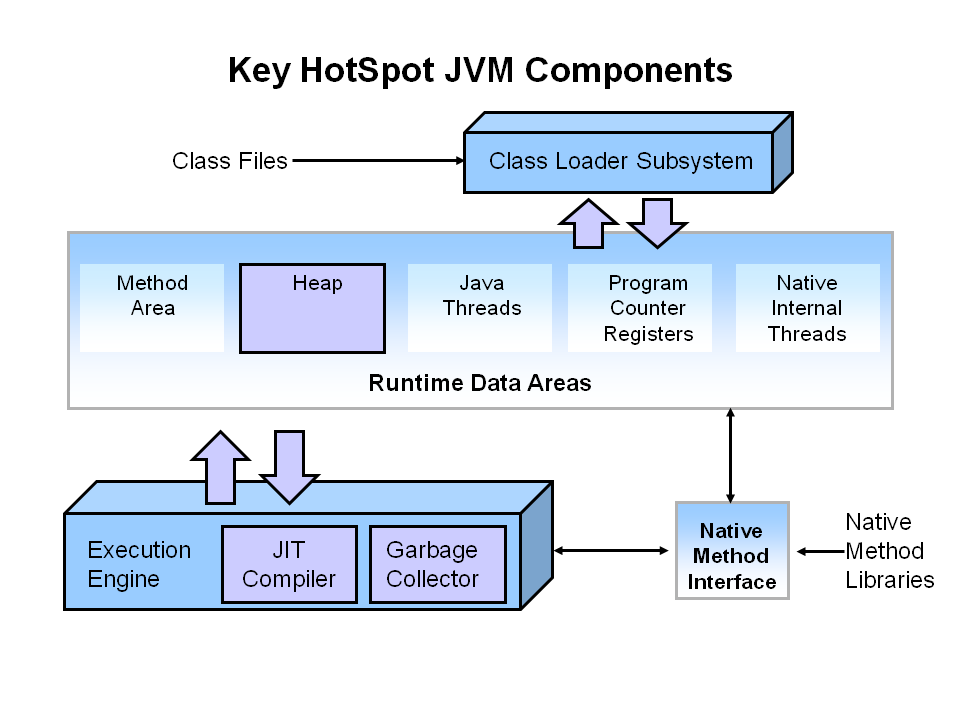
図でハイライト表示したJVMの3つのコンポーネントは、性能をチューニングするときに重要となるものです。ヒープはオブジェクトデータを格納する領域であり、Javaプログラムを起動するときに指定したガーベジコレクタがヒープを管理します。多くのチューニングオプションは、アプリケーションの状況に応じてヒープサイズを指定したり、最適なガーベジコレクションの選択したりするものです。JITコンパイラは性能に大きな影響を及びますが、最近のJVMでは滅多にチューニングする必要はありません。
Performance Basics | 性能の基本
一般的にJavaアプリケーションのチューニングでは、2つの主な目的である「応答性」と「スループット」のうち、どちらか1つに焦点を当てます。このチュートリアルではこの2つの概念を引用します。
Responsiveness | レスポンス性能
レスポンス性能は、アプリケーションまたはシステムが、リクエストされたデータに対してどれだけ迅速に応答するかを示すものです。例を次に示します。
- デスクトップUIがどれだけ速くイベントに応答するか
- Webサイトがどれだけ速くページを返してくるか
- データベースのクエリがどれだけ速く返ってくるか
レスポンス性能を重視するアプリケーションは、長時間の停止を避け、どれだけ短い時間で応答するかを重視します。
Throughput | スループット性能
スループット性能は、指定時間にアプリケーションがどれだけの処理をこなすかに焦点を当てます。スループット性能を計測する方法の例を、次に示します。
- 与えられた時間に処理したトランザクション数
- 1時間にバッチプログラムが消化したジョブ数
- 1時間に処理したデータベースクエリ数
スループット性能を重視するアプリケーションは、長時間のベンチマークを重視します。迅速な応答性を考慮しないので、長時間の停止は問題視しません。
The G1 Garbage Collector | G1ガーベジコレクタ
Garbage-First (G1)コレクタは、サーバスタイルのガーベジコレクタで、マルチプロセッサと大容量メモリを搭載したマシンが対象です。G1コレクタは、高いスループットを達成するために、ガーベジコレクション
(GC) 停止時間の目標に対して高確率で対処します。
- CMSコレクタのように、アプリケーションスレッドと並行して動作できること
- 停止時間を伴うGCを行わずに、断片化した空き領域を結合すること(コンパクション)
- GC停止時間を予測可能であることが求められること
- できるだけスループット性能を低下させないこと
- 巨大なJavaヒープを必要としないこと
G1はConcurrent Mark-Sweepコレクタ (CMS)に取って代わる長期的なものとして計画します。CMSと比較して、G1が良いソリューションとなる相違点があります。1つ目の相違点は、G1はコンパクションを行うコレクタであることです。G1は、きめ細かいフリーリストを使わずに、細かく分割した領域を活用して、十分なコンパクションを行います。コレクタの一部処理を単純化し、潜在的な断片化問題をほとんど除去します。また、G1はCMSコレクタよりもガーベジコレクション停止時間の予測精度を高め、ユーザが希望する停止時間の目標を達成できるようにします。
G1 Operational Overview | G1操作上の概要
シリアル、パラレル、CMSでは、ヒープを固定サイズのYoung世代、Old世代、Permannent世代に分割します。
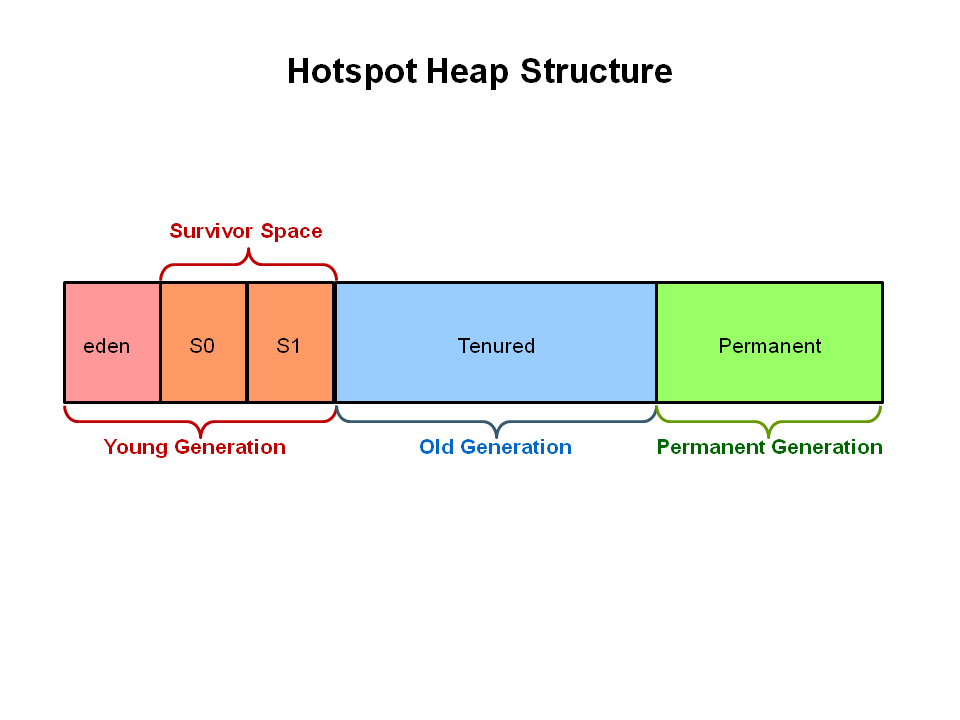
すべてのメモリオブジェクトは、3つの領域のどれかに入ります。
G1コレクタは、異なるアプローチを採ります。
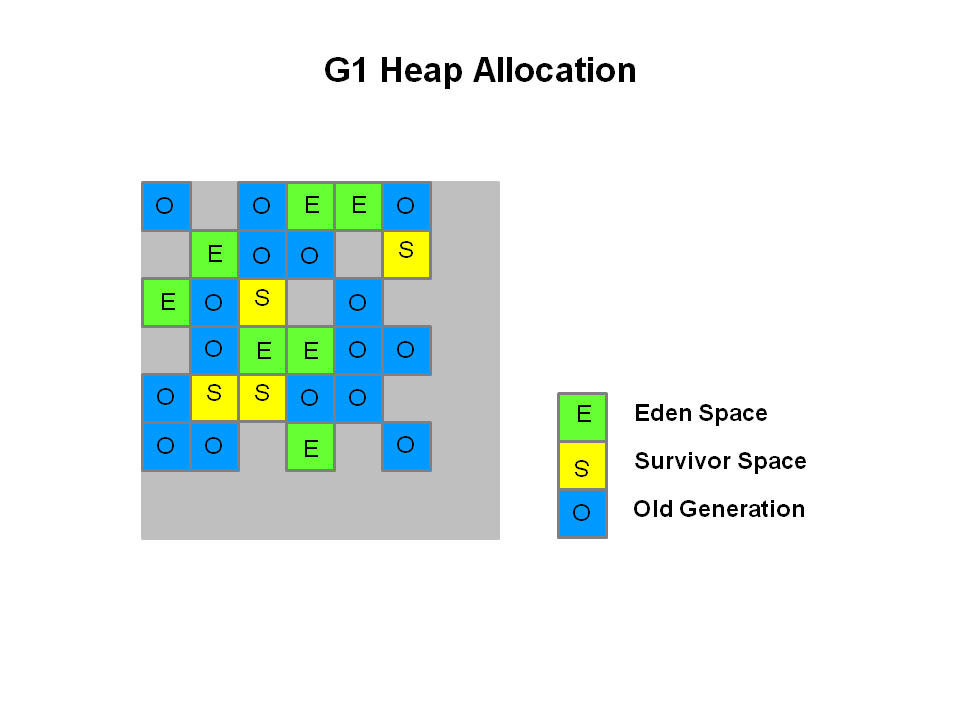
ヒープを1組の同じサイズの領域に分割します。各領域は仮想メモリ内の連続した区間です。各領域は、以前のコレクターと同様にEden、Survivor、Oldを割り当てますが、サイズが固定ではない点で異なります。これはメモリ使用量に応じて、より優れた柔軟性を提供します。
ガーベジコレクションを実行しているとき、G1はCMSコレクタと似た方法で動作します。G1は、ヒープの隅々までオブジェクトの生存を決定するために、並列グローバルマーキングフェーズを実行します。そのマークフェーズが完了すると、G1はどの領域が最も空いているかがわかります。まず、これらの領域上で回収し、通常、多くの空き領域を作ります。この理由により、このガーベジコレクション方式をガーベジファーストと呼びます。名前の通りに、G1は回収可能なオブジェクト(つまりゴミ)でいっぱいになりそうなヒープの領域上で回収とコンパクション活動に集中します。G1はユーザ定義の停止時間目標に対処するために停止予測モデルを使用し、指定された停止時間目標に基づいて回収を行う領域数を選択します。
G1が分割した各領域がいっぱいになると、エバキュエーションを使用して、1つか2つ以上の領域から別の1つの領域にオブジェクトを移動します。そのときにコンパクションも行い、メモリの空き領域を広げます。エバキュエーションは、停止時間を減らしてスループット性能を向上させるために、マルチプロセッサ上では並列処理します。G1は断片化を減らすよう継続的に回収を続け、ユーザが指定した停止時間以内に終わらせるようにします。これにより以前の方式より高い能力を実現します。CMS(コンカレント・マーク・スイープ)ガーベジコレクタは、コンパクションを行いません。ParallelOldガーベジコレクションでは、ヒープ全体のコンパクションのみ行うので停止時間が長くなります。
G1はリアルタイムのコレクタでないことに注意してください。停止時間目標に高い確率で対処しますが、必ずしも確実ではありません。前回のコレクションのデータに基づいて、G1はユーザ指定の停止時間目標以内にどれだけの領域を回収できるかを推測します。G1は複数の領域を回収するコストを計算する精密なモデルを備えていて、停止時間以内に回収できるように、回収対象の領域をどれにするかどのくらいにするかを決めます。
注意: G1は、ConcurrentフェーズとParallelフェーズの両方を持ちます。Concurrentフェーズとは、複数のアプリケーションスレッドと共に1つのGCスレッドが動作し、Refinement、Marking、Cleanupを行うものです。Paralleljフェーズとは、GCを複数スレッドで動作し、Stop the
worldの原因となるものです。FullGCは単一スレッドで動作しますが、アプリケーションを適切にチューニングすれば、FullGCを回避できる場合があります。
G1 Footprint | G1フットプリント
ParallelOldGCまたはCMSコレクタからG1に移行するとき、JVMプロセスのサイズがより大きく見えるでしょう。これはRemembered
SetsとCollection
Setsといった「accounting」データ構造によるものです。
Remembered Sets (RSets)は、担当する領域内で、オブジェクトの参照を追跡します。ヒープ内の領域ごとに1つずつRSetがあります。RSetは領域に対する回収をパラレルかつ独立にできるようにします。Rsetsの全体的なフットプリントの影響は5%未満です。
Collection Sets (CSets)は、GCで回収する領域のセットです。CSets内のすべての生存データは、CGによってエバキュエート(コピー/移動)します。領域のセットは、Eden、Survivor and/or Old世代のどれにもなることができます。CSetsの影響は、JVMのサイズに対して 1%未満です。
Recommended Use Cases for G1 | G1利用を推奨するケース
G1の最初の焦点は、限られたGCレイテンシで、巨大ヒープを必要とするアプリケーションを動作するためのソリューションを提供することです。ヒープサイズが6GB以上であり、安定かつ予測可能な停止時間が0.5秒以下というアプリケーションです。
現在動作中のアプリケーションがCMSまたはParallelOldGCガーベジコレクタのいずれかを使っているとき、次の特徴のいずれかを満たしていれば、G1に変更するメリットがある可能性があります。
- Full GCの実行時間が非常に長いか、Full GCが非常に頻発する
- オブジェクトを割り当てる割合か、Old世代領域に昇進する割合が著しく異なる場合
- ガーベジコレクションまたはコンパクションによる停止時間が長い場合(0.5~1秒を超過)
注意: アプリケーションがCMSまたはParallelOldGCを使っていて、長いガーベジコレクション停止が起きていない場合、G1に変更せずに現在のコレクタを使い続けるのが良いでしょう。G1コレクタに変更することは、最新のJDKを使う場合でも、G1コレクタに変更しなければならないわけではありません。
Reviewing Generational GC and
CMS | 世代GCとCMSの復習
コンカレント・マーク・スイープ(CMS)コレクタは、concurrent
low pause collectorとも呼ばれ、Tenured世代(Old世代のこと)を回収します。CMSは多くのガーベジコレクションの処理を、アプリケーションスレッドと並行して実行することによって、停止時間を最小限にします。通常、CMSは生存オブジェクトのコピーまたはコンパクションは行わないので、断片化が問題になる場合、アプリケーションのヒープサイズを大きくする必要があります。
注意:
CMSはYoung世代上ではパラレルコレクタと同じアルゴリズムを使います。
CMS Collection Phases | CMSコレクションフェーズ
CMSは、ヒープのOld世代上では、次のフェーズで動作します。
Phase
フェーズ |
Description
概要 |
| (1) Initial Mark (Stop the World Event) |
Old世代内のオブジェクトは、Young世代から到着可能なオブジェクトも含め、到着可能なものをマークします。停止時間は一般的にマイナーコレクションの停止時間と比べて短いです。 |
| (2) Concurrent Marking |
Javaアプリケーションスレッドの実行と同時に、Old世代のオブジェクトグラフを横切って、到着可能なオブジェクトを調べます。マークされたオブジェクトからスキャンを始め、ルートから到着可能なすべてのオブジェクトを推移的にマークします。ミューテータ(*1)は、フェーズ(2)、(3)、(5)で実行します。これらのフェーズの実行中に、すべてのオブジェクト(昇進したオブジェクトを含む)はすぐに生存オブジェクトとしてマークされます。
*1: ミューテータはオブジェクトを生成したり参照の更新を行ったりするもの。ミューテータが参照できるオブジェクトは生存オブジェクトで、参照できないオブジェクトは死んだオブジェクトとみなす。 |
| (3) Remark (Stop the World Event) |
コンカレントコレクタがそのオブジェクトを追跡した後に、Javaアプリケーションスレッドによって更新されたために、Concurrent
Markingフェーズで見つけられなったオブジェクトにマークを付けます。 |
| (4) Concurrent Sweep |
Markingフェーズで到着可能でなかったオブジェクトを回収します。死んだオブジェクトのコレクションは、以降のオブジェクト割り当てに備えて、そのオブジェクトの空間をフリーリストに追加します。死んだオブジェクトのCoalescing(*2)はこの時点で起きる場合があります。生存オブジェクトは移動しないことに注意してください。 *2: 連続した空き領域を、1つの空き領域にまとめること。 |
| (5) Resetting |
データ構造をクリアして、次のコンカレントコレクションに向けて準備します。 |
Reviewing Garbage Collection
Steps | ガーベジコレクション手順の復習
次に、CMSコレクタの動作手順を復習しましょう。
Heap Structure for CMS Collector |
CMSコレクタのヒープ構造
ヒープを3つの空間に分割します。

Young世代は、Eden領域と2つのSurvivor領域に分割します。Old世代は1つの連続した空間です。オブジェクトの回収は適宜に行いますが、Full
GCがない限りコンパクションは行いません。
How Young GC works in CMS | CMSにおけるYoung GCの動作について
下図は、アプリケーションがしばらく動作した後のCMSの状況の例を示したものですYoung世代はうす緑色、Old世代は青色です。オブジェクトはOld世代領域で散在しています。

CMSでは、Old世代のオブジェクトを適宜に解放しますが、移動はしません。Full GCがない限り、空き領域のコンパクションは行ないません。
Young Generation Collection | Young世代コレクション
生存オブジェクトはEden空間とSurvivor空間から、他のSurvivor空間にコピーされます。年齢のしきい値に到着した古いオブジェクトはOld世代に移動されます。

After Young GC | Young GC実行後
Young GC実行後、Eden領域をクリアし、片方のSuvivor空間もクリアします。
上図では、Old世代に昇進したオブジェクトを暗い青色で示しています。緑色のオブジェクトは生き残ったYoung世代のオブジェクトで、まだOld世代に移動されていないものです。

Old Generation Collection with
CMS | CMSでのOld世代コレクション
Initial markフェーズとRemarkフェースの2つでStop the
worldが発生します。Old世代の占有率がしきい値を超えると、CMSを起動します。

(1) Initial Markフェーズは短い停止を伴うフェーズであり、生存オブジェクト(到着可能なオブジェクト)をマークします。(2)
Concurrent Markingフェーズは、アプリケーションの実行と並行して生存オブジェクトを探します。(3)
最後にRemarkフェーズでは、前フェーズのConcurrent
Markingフェーズで見つけられなかったオブジェクトを探します。
Old Generation Collection -
Concurrent Sweep | Old世代コレクション – Concurrent Sweep
前のフェーズでマークされなかったオブジェクトは、適宜に解放します。コンパクションは行いません。

Note: Unmarked
objects == Dead Objects
注意: マークされていないオブジェクト == 死亡オブジェクト
注意: マークされていないオブジェクト == 死亡オブジェクト
Old Generation Collection - After
Sweeping | Old世代コレクション
- スイープ後
(4)のSweepフェーズの後に、下図に示すとおり、多くのメモリが解放されています。またコンパクションが行われていないことも示しています。

最後に、CMSコレクタは(5)のResettingフェーズに移行したあと、Old世代の占有率がしきい値に達するまで待機します。
The G1 Garbage Collector Step
by Step
G1コレクタはヒープの割り当て方について異なるアプローチを採っています。以降、G1システムについて、図を交えながらステップバイステップで示します。
G1 Heap Structure | G1ヒープ構造
ヒープは1つのメモリ領域であり、多くの固定サイズの領域に分割します。

JVM起動時に領域のサイズを選択します。JVMは、サイズが1~32MBの2000個前後の領域を、一般的な目標とします。
G1 Heap Allocation | G1ヒープ割り当て
実際に、これらの領域をEden領域、Survivor領域およびOld世代領域の論理表現にマップします。
図では、領域のロールに応じて色を使い分けています。生存オブジェクトは1つの領域から他方の領域にエバキュエート(コピーまたは移動)します。アプリケーションスレッドすべてを停止するかどうかに関わらず、各領域を並列して回収するよう設計しています。
図示のとおり、各領域はEden領域、Survivor領域およびOld世代領域として割り当て可能です。さらにHumongous領域と呼ばれる4番目のタイプがあります。Humongous領域は、標準的な領域(Eden領域、Survivor領域、Old世代のこと)のサイズの50%かそれ以上の巨大オブジェクトを保持します。巨大オブジェクトは1組の連続した領域に保存します。最後にはHumongous領域は、(訳注:オブジェクトを破棄すれば、)ヒープの未使用領域になります。
注意: 現時点では、Humongous領域の回収は最適化しません。したがって、巨大なサイズのオブジェクトを生成しないようにしてください。
Young Generation in G1 | G1のYoung世代
ヒープをおおよそ2000の領域に分割します。領域の最少サイズは1MBで、最大サイズは32MBです。青色の領域はOld世代のオブジェクトを保持し、緑色の領域はYoung世代のオブジェクトを保持します。

以前のガーベジコレクタのように、Young世代は連続した領域でなければならないわけではありません。
A Young GC in G1 | G1のYoung GC
生存オブジェクトは1個またはそれ以上のSurvivor領域にエバキュエート(コピーまたは移動)します。年齢のしきい値に達したら、いくつかのオブジェクトはOld世代領域に昇進します。

Young GCはStop the
world (STW)を起こします。Eden領域とSuvivor領域のサイズは、次回のYoung GCに向けて計算します。このAccounting情報は、領域サイズを計算するために保持します。停止時間の目標などは考慮します。
このアプローチは、領域サイズの調整を非常に容易にし、必要に応じて領域のサイズを大きくしたり小さくしたりします。
End of a Young GC with G1 | G1でのYoung GCの終了
生存オブジェクトは、Survivor領域かOld世代領域にエバキュエートします。

図では、Old世代領域に昇進したオブジェクトを暗い青色で、Survivor領域にコピーしたオブジェクトを緑色で示します。(訳注:図に青色がないのは作成ミス?)
G1のYoung世代についてまとめたものを、次に列挙します。
- 1つのメモリ領域であるヒープは、複数の領域に分割します。
- Young世代領域は非連続の領域のセットであり、必要に応じてサイズが動的に変化します。
- Young世代GCまたはYoung GCはStop the worldを起こし、すべてのアプリケーションスレッドが停止します。
- Young GCは複数スレッドを使用して並行に処理します。
- 生存オブジェクトは新しいSuvivor領域またはOld世代領域にコピーします。
Old Generation Collection with
G1 | G1でのOld世代コレクション
CMSコレクタと同様、G1コレクタもOld世代の回収を低負荷で実行します。
G1 Collection Phases -
Concurrent Marking Cycle Phases
G1コレクションのフェーズ
- コンカレント・マーキング・サイクルフェーズ
G1コレクタは、ヒープのOld世代領域に対して、下表に示すフェーズで動作します。いくつかのフェーズはYoung世代コレクションの一部のフェーズである点に注意してください。
| Phase |
Description |
| (1) Initial Mark (Stop the World Event) |
Stop the worldを起こします。G1では、通常のYoung GCに便乗します。Old世代のオブジェクトを参照している可能性があるSurvivor領域(Root領域)をマークします。 |
| (2) Root Region Scanning |
Survivor領域をスキャンし、Old世代への参照があるかどうかを調べます。アプリケーションスレッドと並行して動作します。このフェーズは、(次の?)Young GCが発生する前に完了していなければなりません。 |
| (3) Concurrent Marking |
ヒープ全体を探して生存オブジェクトを見つけます。アプリケーションスレッドと並行して動作します。このフェーズは(次の)Young GCによって中断されることがあります。 |
| (4) Remark (Stop the World Event) |
ヒープ上の生存オブジェクトのマークを完了します。Snapshot-At-The-Beginning
(SATB)というアルゴリズムを使います。CMSのRemarkフェーズより高速です。 |
| (5) Cleanup (Stop the World Event and Concurrent) |
o 生存オブジェクトのAccountingを実行し、完全な空き領域にします(Stop
the World発生)。
o Remember Setをクリアします
o 空き領域をリセットし、フリーリストに返します(並列処理)
|
| (*) Copying (Stop the World Event) |
新しい未使用利用域に生存オブジェクトをエバキュエート(コピー)します。Stop the worldを起こします。このフェーズはYoung世代領域に対しても実行可能です。Young世代に対して実行する場合は"[GC pause (young)]"とログ出力し、Young世代とOld世代の両方に対して実行する場合は"[GC Pause (mixed)]"とログ出力します。 |
G1 Old Generation Collection
Step by Step
G1のOld世代回収のステップ・バイ・ステップ
G1コレクタにおいて、これらのフェーズがどのようにOld世代で相互作用するか見ていきましょう。
Initial Marking Phase | Initial
Markingフェーズ
生存オブジェクトの初期マーキングは、Young世代ガーベジコレクションに便乗します。"
GC pause (young)(inital-mark)"とログ出力します。
Concurrent Marking Phase | Concurrent
Markingフェーズ
もし空き領域が見つかったら(図で"X"の部分)、すぐRemarkフェーズで削除します。また生存を決めるAccounting情報をすぐ計算します。
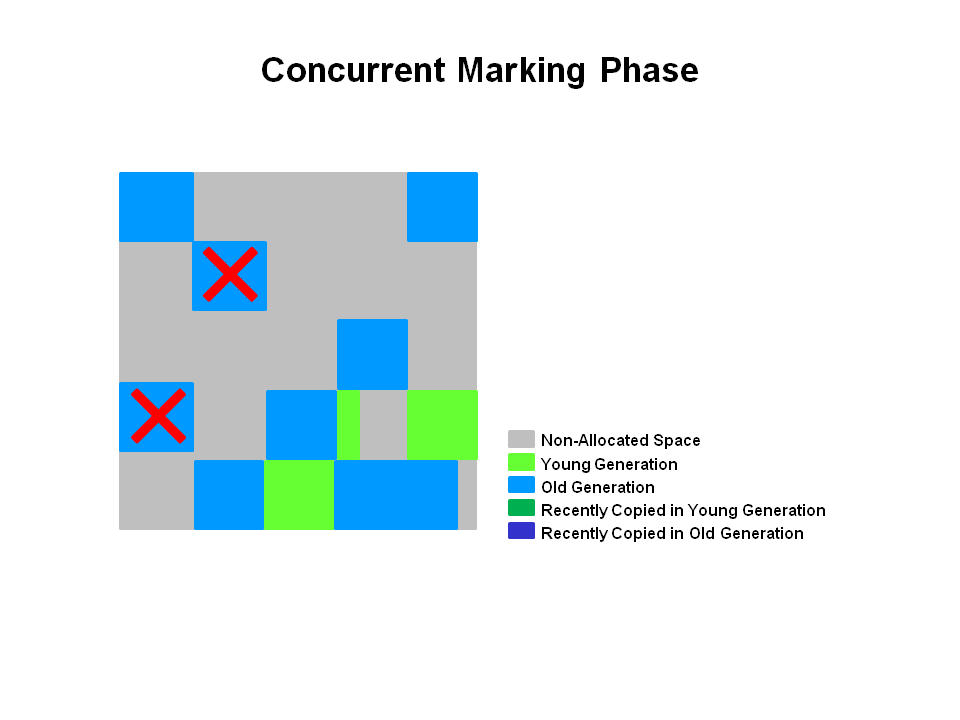
Remark Phase | Remarkフェーズ
空き領域を削除し、回収します。そして、領域の生存を計算します。

Copying/Cleanup Phase | Copying/Cleanupフェーズ
G1は回収が速くできるように生存オブジェクトが少ない領域を選択し、Young GCでそれらの領域を回収します。Young世代とOld世代を同時に回収するので、"
[GC pause (mixed)]"とログ出力します。
After Copying/Cleanup Phase | Copying/Cleanupフェーズ後
選択した領域の回収およびコンパクションが完了します。下図の藍色と深緑色で示している部分です。

Summary of Old Generation GC | Old世代GCの概要
Old世代に対するG1ガーベジコレクションに関するキーポイントを、次に列挙します。
- Concurrent Marking Phase | Concurrent Markingフェーズ
- アプリケーション実行中に、並列して生存情報を計算します
- 生存情報により、エバキュエーションによる停止中にどの領域を回収するのがベストかを確認します
- CMSのSweepフェーズがありません
- Remark Phase | Remarkフェーズ
- Snapshot-at-the-Beginning (SATB)アルゴリズムを使用し、CMSよりも高速に動作します
- 空き領域を完全に回収します
- Copying/Cleanup Phase | Copying/Cleanupフェーズ
- Young世代とOld世代を同時に回収します
- オブジェクトの生存率に基づいてOld世代領域を選択します
Command Line Options and Best
Practices
このセクションでは、G1の様々なコマンドライン・オプションを見ていきましょう。
Basic Command Line | 基本的なオプション
G1コレクタを有効化:-XX:+UseG1GC次は、"JDK demos and samples"に含まれているJava2Demoを起動するコマンドラインのサンプルです
java -Xmx50m -Xms50m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -jar c:\javademos\demo\jfc\Java2D\Java2demo.jar
Key Command Line Switches | 主要なオプション
-XX:+UseG1GC –
G1ガーベジコレクタの使用をJVMに指示する
-XX:MaxGCPauseMillis=200 –
最大のGC停止時間目標を設定します。ソフトな目標であり、JVMは目標達成に努めますが、ベストエフォートなので必ずしも達成できるとは限りません。デフォルト値は200ミリ秒です。
-XX:InitiatingHeapOccupancyPercent=45 –
G1がコンカレントGCのサイクルを起動する契機となる(全体の)ヒープの占有率です。1つの世代ではなく全体ヒープの占有率です。0の場合、恒常的にGCを繰り返すことを意味します。デフォルトは45(占有率45%)です。
Best Practices | ベストプラクティス
以下にG1のベストプラクティスをいくつか示します。
Do not Set Young Generation Size | Young世代のサイズを設定しないこと
はっきり言って、-XmnオプションでYoung世代のサイズを設定することは、G1コレクタのデフォルト動作に干渉します。
- G1はもはや停止時間目標を顧慮しなくなります。本質的には、Young世代のサイズの設定は、停止時間目標を無効にします。
- G1はもはやYoung世代領域を必要に応じて拡張・請負をしなくなります。サイズが固定になり、サイズの変更もありません。
Response Time Metrics | 時間メトリクスの顧慮
-
XX:MaxGCPauseMillis=<N>オプションを設定して測定基準として平均応答時間(ART)を使う際、設定値の90%以上は目標時間を超えてしまうことを考慮してください。ユーザリクエストの90%は、目標以上の応答時間が得られない可能性があるためです。停止時間は目標であって、常に達成できるとは限らないことを念頭に置いてください。
What is an Evacuation Failure? | エバキュエーションの失敗とは?
JVM実行時に、Suvivor領域か昇進オブジェクトに対するGC実行中にヒープ領域が不足すると、昇進に失敗します。ヒープはすでに最大なので拡張できません。
-XX:+PrintGCDetailsオプションを指定すればTo領域が満杯になったことを示すGCログを出力します。ログ出力はコストが高いので注意してください。- GCは空き領域を作るために継続します。
- コピーに成功しなかったオブジェクトは、Old世代へ適宜にコピーしなければなりません。
- CSetにある領域のRSetsの更新を再実行しなければなりません。
- すべてのステップはコストが高いです。
How to avoid Evacuation Failure |
エバキュエーションの失敗を回避するには?
エバキュエーションの失敗を回避するには、次のオプションを考慮してください。
- ヒープサイズの拡大
-XX:G1ReservePercent=nオプションで拡大します。デフォルトは10です- G1はTo領域が要求される場面で、予備メモリ領域(予約済みメモリ領域)の空き領域の維持を試みることによりfalse ceiling(吊天井)を生成します。
- Markingサイクルを早めに開始してください
-XX:ConcGCThreads=nオプションを使って、Markingを実行するスレッドの個数を増やしてください。
Complete List of G1 GC Switches
| G1 GCの完全なオプション一覧
下表はG1
GCオプションの完全な一覧です。前述したベストプラクティスを考慮の上でオプションを使ってください。
Option
and Default Value
|
Description
|
| -XX:+UseG1GC |
ガーベジファースト(G1)コレクタを使用します。 |
| -XX:MaxGCPauseMillis=n |
GCによる最大停止時間の目標を設定します。ソフトな目標であり、JVMは指定された数値を達成するように努めますが、ベストエフォートです。 |
| -XX:InitiatingHeapOccupancyPercent=n |
コンカレントCGのサイクルを起動する契機となる(全体)ヒープの占有率です。ヒープ全体の占有率であり、1つの世代ではありません。0の場合、恒常的にGCサイクルを継続します。デフォルトは45(占有率45%)です。
|
| -XX:NewRatio=n |
New世代/Old世代のサイズの割合です。デフォルト値は2です。 |
| -XX:SurvivorRatio=n |
Eden領域/Survivor領域のサイズの割合です。デフォルト値は8です。 |
| -XX:MaxTenuringThreshold=n |
Old世代へ昇進するしきい値です。デフォルト値は15です。 |
| -XX:ParallelGCThreads=n |
GCの各Parallelフェーズにて、GCを実行するスレッドの個数を設定します。デフォルト値は、JVMが動作するプラットフォームによって異なります。(訳注:Parallelフェーズは、アプリケーションスレッドを止めてGCスレッドだけを並行実行する) |
| -XX:ConcGCThreads=n |
コンカレントGCのスレッド数を設定します。デフォルト値はJVMが動作するプラットフォームによって異なります。(訳注:Concurrentフェーズは、アプリケーションスレッドと並行してGCを実行する)
|
| -XX:G1ReservePercent=n |
false ceiling(吊天井)として予約するヒープ総量を設定します。これはOld世代への昇進に失敗する可能性を減らすためです。デフォルト値は10です。
|
| -XX:G1HeapRegionSize=n |
G1ではJavaヒープは非公開サイズの領域に分割します。分割した個々の領域のサイズを設定します。デフォルト値はヒープのサイズに基づいて自動的に決定します(エルゴノミックス)。最小値は1MBで最大値は32MBです。
|
Logging
GC with G1 | G1のログ出力
最後のこのトピックでは、ログ情報からG1コレクタの性能を分析する方法を説明します。このセクションでは、ログ情報からデータや情報を収集するためのオプションの概観を示します。
Setting the Log Detail | 詳細ログの設定
ログの詳細レベルを3段階で設定できます。
(1)
-verbosegc (-XX:+PrintGCと同様)
ログの詳細レベルを"fine"に設定します。
Sample Output | 出力例
[GC pause (G1 Humongous Allocation) (young) (initial-mark) 24M- >21M(64M), 0.2349730 secs]
[GC pause (G1 Evacuation Pause) (mixed) 66M->21M(236M), 0.1625268 secs]
(2)
-XX:+PrintGCDetails ログの詳細レベルを"finer"に設定します。次の情報を出力します。- 各フェーズの所要時間の平均値、最小値および最大値
- ルート・スキャン、RSet更新(処理したバッファ情報で)、RSetのスキャン、オブジェクトのコピーおよび終了(試行回数)
- CSetの選択、参照処理、参照のエンキューおよびCSetの解放などの所要時間
- Eden領域、Survivor領域およびヒープ全体の使用量
Sample Output | 出力例
[Ext Root Scanning (ms): Avg: 1.7 Min: 0.0 Max: 3.7 Diff: 3.7]
[Eden: 818M(818M)->0B(714M) Survivors: 0B->104M Heap: 836M(4096M)->409M(4096M)]
(3)
-XX:+UnlockExperimentalVMOptions -XX:G1LogLevel=finestログの詳細レベルを"finest"に設定します。"finer"の内容に加えて、個々のワーカースレッドの情報も出力します。[Ext Root Scanning (ms): 2.1 2.4 2.0 0.0
Avg: 1.6 Min: 0.0 Max: 2.4 Diff: 2.3]
[Update RS (ms): 0.4 0.2 0.4 0.0
Avg: 0.2 Min: 0.0 Max: 0.4 Diff: 0.4]
[Processed Buffers : 5 1 10 0
Sum: 16, Avg: 4, Min: 0, Max: 10, Diff: 10]
Determining Time | 時間の特定
次の2つのオプションは、GCに要した時間を出力します。
(1)
-XX:+PrintGCTimeStamps -
JVM起動後の経過時間を出力します。
Sample Output | 出力例
1.729: [GC pause (young) 46M->35M(1332M), 0.0310029 secs]
(2)
(2)
-XX:+PrintGCDateStamps -
Adds a time of day prefix to each entry.(2)
-XX:+PrintGCDateStamps -
ログの先頭に日付と時間を追加します。 2012-05-02T11:16:32.057+0200: [GC pause (young) 46M->35M(1332M), 0.0317225 secs]
Understanding G1 Log | G1ログを理解する
このセクションでは、ログを理解するために、実際のGCログ出力を使っていくつかの用語を定義します。以降、ログ出力の例を、用語と値の説明を交えて紹介します。
G1
Logging Terms Index | G1ログ用語の一覧
l CSet
l External
Root Scanning
l Free
CSet
l GC
Worker End
l GC
Worker Other
l Object
Copy
l Other
l Parallel
Time
l Ref
Eng
l Ref
Proc
l Scanning
Remembered Sets
l Termination
Time
l Update
Remembered Set
l Worker
Start
Parallel Time
414.557: [GC pause (young), 0.03039600 secs] [Parallel Time: 22.9 ms]
[GC Worker Start (ms): 7096.0 7096.0 7096.1 7096.1 706.1 7096.1 7096.1 7096.1 7096.2 7096.2 7096.2 7096.2
Avg: 7096.1, Min: 7096.0, Max: 7096.2, Diff: 0.2]
Parallel Time –
Parallelの全体な経過時間(停止時間内に処理した時間)
Worker Start – ワーカースレッドが起動した時間のタイムスタンプ
Note: スレッドIDThe logs are ordered on thread id and are consistent on each entry
Worker Start – ワーカースレッドが起動した時間のタイムスタンプ
Note: スレッドIDThe logs are ordered on thread id and are consistent on each entry
[Ext Root Scanning (ms): 3.1 3.4 3.4 3.0 4.2 2.0 3.6 3.2 3.4 7.7 3.7 4.4
Avg: 3.8, Min: 2.0, Max: 7.7, Diff: 5.7]
External root
scanning –
External Rootのスキャンに要した時間
(例:ヒープ領域へのポイントを示すSystem
dictionaryなど)
[Update RS (ms): 0.1 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 Avg: 0.0, Min: 0.0, Max: 0.1, Diff: 0.1]
[Processed Buffers : 26 0 0 0 0 0 0 0 0 0 0 0
Sum: 26, Avg: 2, Min: 0, Max: 26, Diff: 26]
Update
Remembered Set -
バッファはConcurrent
refinementスレッドによる処理が未実施であれば、停止を開始する前に更新されなければなりません。処理時間はカードの密度に依存し、カードが多ければ多いほど処理時間が長くなります。
[Scan RS (ms): 0.4 0.2 0.1 0.3 0.0 0.0 0.1 0.2 0.0 0.1 0.0 0.0 Avg: 0.1, Min: 0.0, Max: 0.4, Diff: 0.3]F
Scanning
Remembered Sets -
Collection Setへのポイントを探します。
[Object Copy (ms): 16.7 16.7 16.7 16.9 16.0 18.1 16.5 16.8 16.7 12.3 16.4 15.7 Avg: 16.3, Min: 12.3, Max: 18.1, Diff: 5.8]
Object copy –
個々のスレッドがオブジェクトのコピーとエバキュエーションに消費した時間
[Termination (ms): 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 Avg: 0.0, Min: 0.0, Max: 0.0, Diff: 0.0] [Termination Attempts : 1 1 1 1 1 1 1 1 1 1 1 1 Sum: 12, Avg: 1, Min: 1, Max: 1, Diff: 0]
Termination
time -
ワーカースレッドはその特定オブジェクトのコピーとスキャンが終了したとき、終了処理に入ります。スチールする処理を探し、その処理が完了したら、再び終了処理に入ります。終了試行回数は、スチール処理の試行回数の総数です。
[GC Worker End (ms): 7116.4 7116.3 7116.4 7116.3 7116.4 7116.3 7116.4 7116.4 7116.4 7116.4 7116.3 7116.3
Avg: 7116.4, Min: 7116.3, Max: 7116.4, Diff: 0.1]
[GC Worker (ms): 20.4 20.3 20.3 20.2 20.3 20.2 20.2 20.2 20.3 20.2 20.1 20.1
Avg: 20.2, Min: 20.1, Max: 20.4, Diff: 0.3]
GC worker end
time –
個々のGCワーカーの停止時間のタイムスタンプ
GC worker time – 個々のGCワーカースレッドの消費時間
GC worker time – 個々のGCワーカースレッドの消費時間
[GC Worker Other (ms): 2.6 2.6 2.7 2.7 2.7 2.7 2.7 2.8 2.8 2.8 2.8 2.8
Avg: 2.7, Min: 2.6, Max: 2.8, Diff: 0.2]
GC worker
other –
個々のワーカースレッドが先述のどのフェーズにも属さなかった時間。この値は小さくあるべきです。極端に高い数値が出た前例では、JVMの他の部分でボトルネックに起因していました。たとえば、TieredによるCode
Cache占有の増加です。(訳注:Tired
CompilationとはJITで採用しているコンパイル技術→"Java HotSpot™ Virtual
Machine Performance EnhancementsのTiered Compilation"を参照)
[Clear CT: 0.6 ms]
Other
[Other: 6.8 ms]
GC停止時にシーケンシャルで動作するさまざまなフェーズでの所要時間。
[Choose CSet: 0.1 ms]
領域セットでの回収を終了させるのに要した時間。通常、短い時間です。Old世代の場合、少し長くなります。
[Ref Proc: 4.4 ms]
GCの前フェーズから参照しているSoftリファレンス、Weakリファレンスの処理に要した時間。
[Ref Enq: 0.1 ms]
Softリファレンス、Weakリファレンスなどを保留リストに入れるのに要した時間。
[Free CSet: 2.0 ms]
回収済みの領域セットおよびRSetsを解放するのに要した時間。
このOBEでは、JVM とG1ガーベジコレクタの概要に触れました。最初にヒープとガーベジレクタがJVMの主要なものであることを学びました。次に、CMSコレクタとG1コレクタがどのように動作するかを復習しました。その次にG1コマンドラインオプションとベストプラクティスについて学びました。最後に、GCログが出力するデータについて学びました。
このチュートリアルでは、次を学びました:
- The components of the Java JVM
- An overview of the G1 Collector
- A review of the CMS collector
- A review of the G1 collector
- Command line switches and best practices
- Logging with G1
Resources | 関連文献
For more information and related
information please see these site and links.
Credits | 謝辞
- Curriculum Developer: Michael J Williams
- QA: Krishnanjani Chitta
こんばんは。
返信削除豊富な情報、ありがたいです!
6年前の記事ですので、最近のJavaの情報は他の記事を参照していただければと思います。
削除